

How To Load Data Into Hadoop Hdfs
Hortonworks data scientists focus on data ingestion, discussing various tools and techniques to import datasets from external sources into Hadoop. They begin with describing the Hadoop information lake concept and and then movement into the various means data can be used by the Hadoop platform. The ingestion targets ii of the more popular Hadoop tools—Hive and Spark.
This chapter is from the volume
-
You can take data without data, simply you cannot have information without information.
-
Daniel Keys Moran
No matter what kind of data needs processing, there is often a tool for importing such data from or exporting such data into the Hadoop Distributed File System (HDFS). Once stored in HDFS the data may be candy by whatever number of tools available in the Hadoop ecosystem.
This chapter begins with the concept of the Hadoop data lake and then follows with a general overview of each of the chief tools for data ingestion into Hadoop—Spark, Sqoop, and Flume—along with some specific usage examples. Workflow tools such every bit Oozie and Falcon are presented as tools that help in managing the ingestion process.
Hadoop as a Data Lake
Data is ubiquitous, but that does non ever mean that it'southward piece of cake to shop and access. In fact, many existing pre-Hadoop data architectures tend to exist rather strict and therefore difficult to work with and make changes to. The data lake concept changes all that.
So what is a information lake?
With the more traditional database or data warehouse approach, calculation data to the database requires data to exist transformed into a pre-determined schema before it can be loaded into the database. This step is oft chosen "extract, transform, and load" (ETL) and often consumes a lot of time, effort, and expense before the information tin can exist used for downstream applications. More than importantly, decisions nearly how the data volition be used must be made during the ETL step, and afterwards changes are costly. In addition, data are often discarded in the ETL step considering they do not fit into the data schema or are deemed un-needed or not valuable for downstream applications.
One of the bones features of Hadoop is a central storage space for all data in the Hadoop Distributed File Systems (HDFS), which make possible cheap and redundant storage of big datasets at a much lower cost than traditional systems.
This enables the Hadoop information lake approach, wherein all data are often stored in raw format, and what looks like the ETL step is performed when the information are candy by Hadoop applications. This approach, too known every bit schema on read, enables programmers and users to enforce a construction to arrange their needs when they admission data. The traditional data warehouse arroyo, likewise known as schema on write, requires more upfront design and assumptions about how the data volition somewhen exist used.
For data scientific discipline purposes, the capability to proceed all the data in raw format is extremely beneficial since often information technology is not articulate upward front end which data items may be valuable to a given data scientific discipline goal.
With respect to big data, the data lake offers iii advantages over a more traditional arroyo:
-
All data are available. At that place is no demand to make any assumptions virtually future information use.
-
All data are sharable. Multiple concern units or researchers can utilize all available data 1 , some of which may not have been previously available due to data compartmentalization on disparate systems.
-
All access methods are available. Any processing engine (MapReduce, Tez, Spark) or application (Hive, Spark-SQL, Pig) can be used to examine the information and process it as needed.
To exist clear, data warehouses are valuable business organization tools, and Hadoop is designed to complement them, non supercede them. Nonetheless, the traditional data warehouse technology was adult earlier the information lake began to make full with such large quantities of information. The growth of new data from disparate sources including social media, click streams, sensor data, and others is such that nosotros are starting to rapidly fill the information lake. Traditional ETL stages may not be able to continue up with the rate at which data are entering the lake. There volition be overlap, and each tool will address the demand for which information technology was designed.
The difference betwixt a traditional data warehouse and Hadoop is depicted in Effigy four.ane.
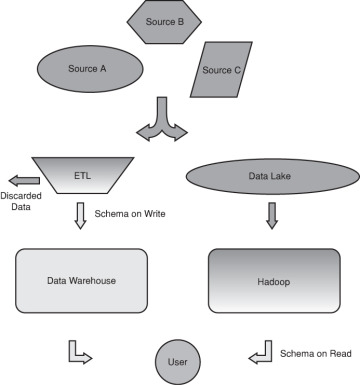
Effigy 4.1 The information warehouse versus the Hadoop data lake.
Different data sources (A, B, C) can exist seen inbound either an ETL process or a data lake. The ETL process places the data in a schema as it stores (writes) the information to the relational database. The data lake stores the information in raw form. When a Hadoop application uses the information, the schema is applied to information equally they are read from the lake. Note that the ETL pace often discards some data as part of the procedure. In both cases the user accesses the data they need. However, in the Hadoop instance information technology can happen every bit presently every bit the data are bachelor in the lake.

How To Load Data Into Hadoop Hdfs,
Source: https://www.informit.com/articles/article.aspx?p=2756471
Posted by: wagnergear1974.blogspot.com
0 Response to "How To Load Data Into Hadoop Hdfs"
Post a Comment